在 DeepSeek 24 小时前刚刚发布了 V3 模型 0324 版本更新之后,OpenAI 似乎真的有点「不甘示弱」的较劲感,在北京时间 3 月 26 日凌晨宣布了新产品的发布预告。

虽然在正式开始之前,有一些传言猜测本次有可能发布 GPT-5,但根据以往 OpenAI 的各种产品发布节奏来看,这次并不会是一次重磅更新,但本次直播中,发布的整合进 ChatGPT 中的新版 Sora,还是给大家带来的意料之外的「节目效果」。
目前,整合进 ChatGPT 中的 Sora,相比于独立应用版本,能力暂时被局限在了图像生成,但据 OpenAI 在直播中介绍,该模型比之前的模型有了质的飞跃。
据介绍,开发团队使用了GPT-4o「全模态」(或可以生成文本、图像、音频和视频等任何类型数据的模型)能力为基础,来开发这个版本的 Sora。因此用户可以直接说出自己的需求,甚至上传或者拍一张照片,作为提示词来使用。
比如直播现场的演示环节,就直接用手机给 Sam Altman 在内的三人来了张自拍,并要求 Sora 生成一张「动漫风格的版本」。
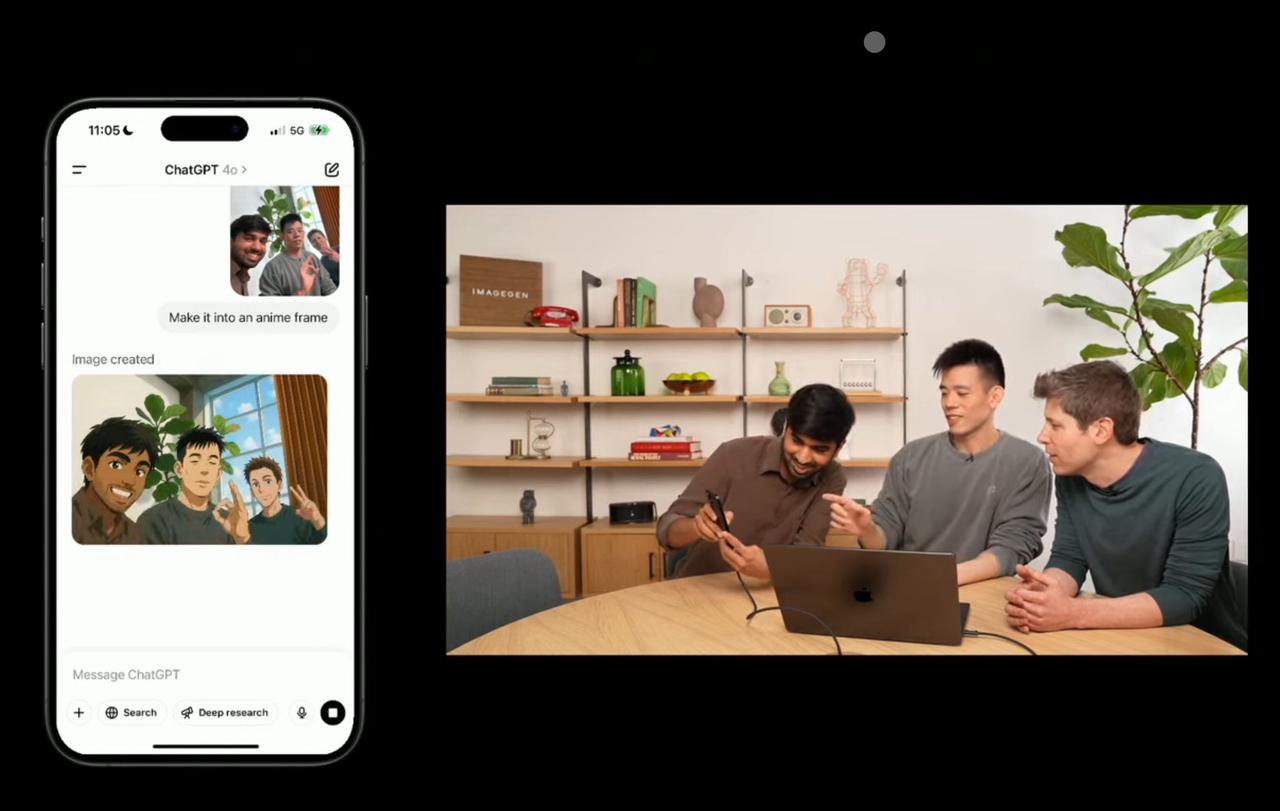
这还没完,他们三人甚至还现场演示了让 Sora 在图片上添加一段文本「Feel The AGI」(感受通用人工智能)。现场画了第一张新版 Sora 的表情包。
这个现场生成的表情包不仅文本准确清晰,并且准确理解了当代流行梗图中的包括粗体字等必备元素,已经能直接拿来当梗图发到各种群里了。

由于是 OpenAI 官方带头整活,评论区也有不少用户也被激发热情,尝试着把相同的提示词喂给 Grok,用相同的提示词和照片,生成同样风格的内容 ———— 但显然效果还是比新版 Sora 差了不少,反而带来了更喜感的效果。

除了带头画梗图,OpenAI 还演示了新版本 Sora 在文本渲染方面的改进,可以让在图像上生成没有拼写错误的连贯文本的成功率明显提升。
在另一个演示场景中,OpenAI 团队让 Sora 去生成一幅用于理解相对论的漫画卡片。
不同于以往生图模型中,在文本生成部分经常容易变得混乱不堪,甚至是「AI 造字」的情况发生,新版 Sora 其原生图像生成,生成的文本,已经没有任何明显错乱,甚至还在漫画生成了非常自然流畅的日文,意外的让日文社区的不少日本用户「炸锅」。