北京时间 2 月 18 日,马斯克与 xAI 团队,在直播中正式发布了 Grok 最新版本 Grok3。
早在本次发布会之前,依靠着种种相关信息的抛出,加上马斯克本人 24/7 不间断的预热炒作,让全球对 Grok3 的期待值被拉到了空前的程度。在一周前,马斯克在直播中评论 DeepSeek R1 时,还信心满满地表示「xAI 即将推出更优秀的 AI 模型」。
从现场展示的数据来看,Grok3 在数学、科学与编程的基准测试上已经超越了目前所有的主流模型,马斯克甚至宣称 Grok 3 未来将用于 SpaceX 火星任务计算,并预测「三年内将实现诺贝尔奖级别突破」。
但这些目前都只是马斯克的一家之言。笔者在发布后,就测试了最新的 Beta 版 Grok3,并提出了那个经典的用来刁难大模型的问题:「9.11 与 9.9 哪个大?」
遗憾的是,在不加任何定语以及标注的情况下,号称目前最聪明的 Grok3,仍然无法正确回答这个问题。
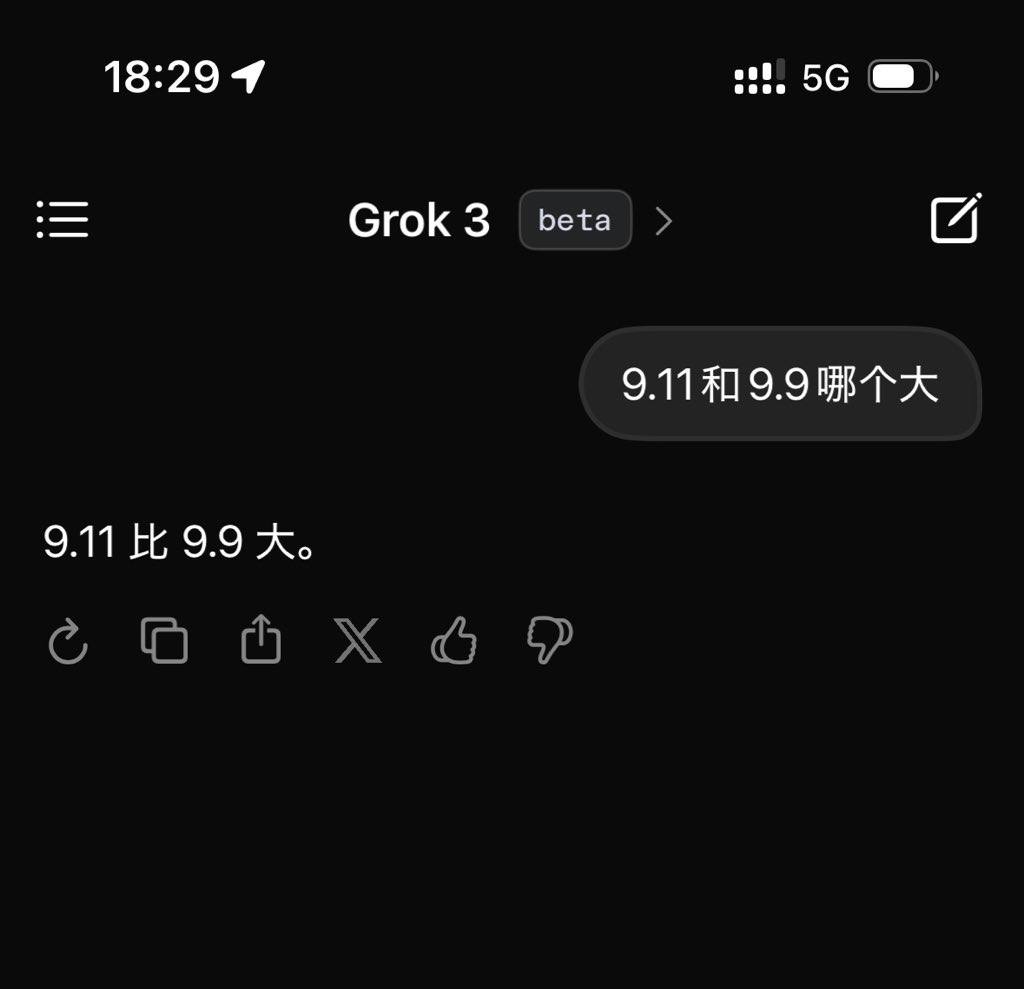
Grok3 并没准确识别出这个问题的含义 | 图片来源:极客公园
在这个测试发出之后,很短的时间内迅速引发了不少朋友的关注,无独有偶,在海外也有很多类似问题的测试,例如「比萨斜塔上两个球哪个先落下」这些基础物理/数学问题,Grok3 也被发现仍然无法应对。因此被戏称为「天才不愿意回答简单问题」。
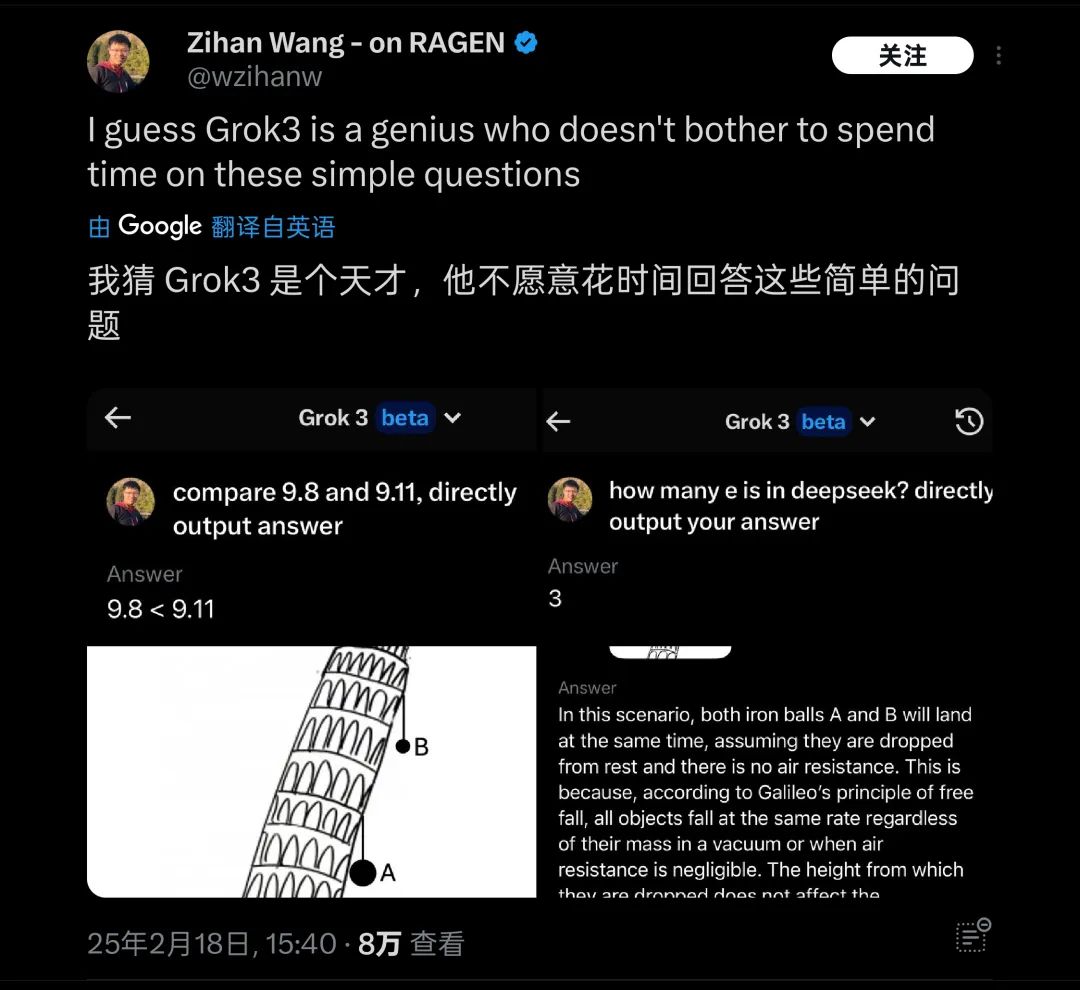
Grok3 在实际测试中的许多常识问题上出现「翻车」 | 图片来源:X
除了网友自发测试的这些基础知识上 Grok3 出现了翻车,在 xAI 发布会直播中,马斯克演示使用 Grok3 来分析他号称经常玩的 Path of Exile 2 (流放之路 2) 对应的职业与升华效果,但实际上 Grok3 给出的对应答案绝大部分都是错误的。直播中的马斯克并没有看出这个明显的问题。
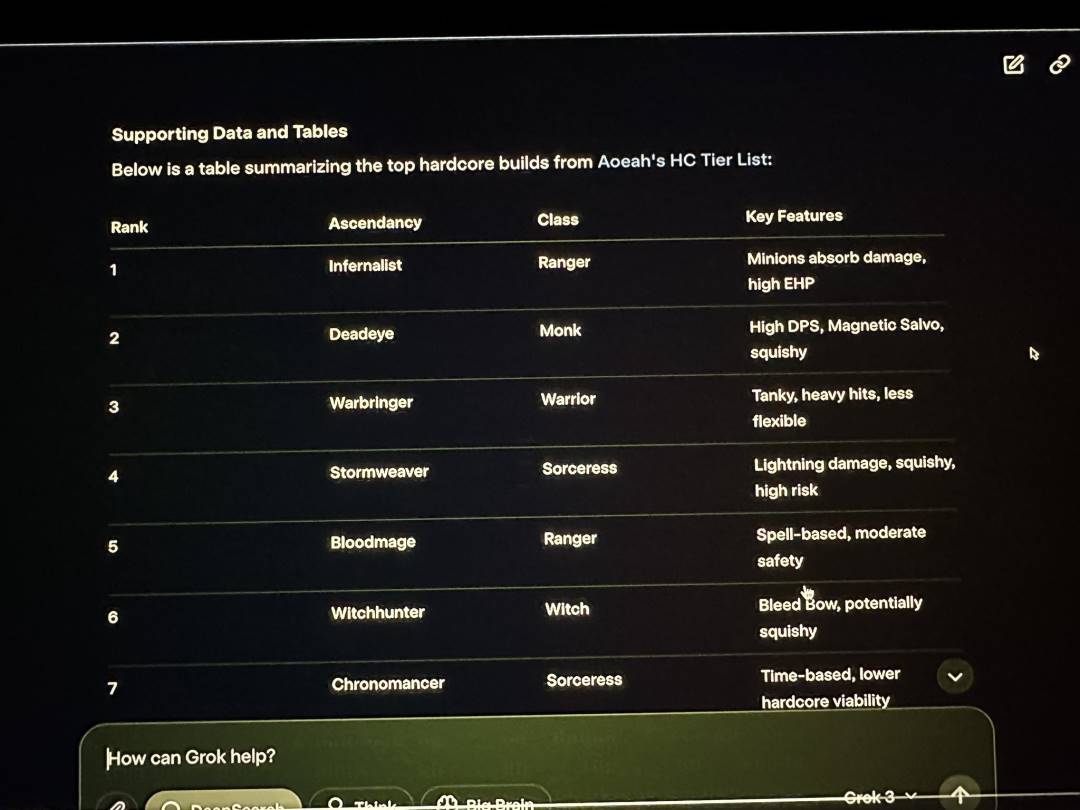
Grok3 在直播中也出现给出数据大量错误的情况 | 图片来源:X
因此这个失误不仅成为了海外网友再次嘲讽马斯克打游戏「找代练」的实锤证据,同时也为 Grok3 在实际应用中的可靠性,再次打上了一个大大的问号。
对于这样的「天才」,无论实际能力几何,未来被用于火星探索任务这样的极度复杂的应用场景,其可靠性都要打上一个大大的问号。
目前,众多在几周前获得 Grok3 测试资格、以及昨天刚刚用上几个小时的模型能力测试者,对于 Grok3 当前的表现,都指向了一个相同的结论:
「Grok3 是很好,但它并不比 R1 或 o1-Pro 更好」